Hello,
In this thread, I want to propose a LIP for the roadmap objective Introduce universal serialization method. The proposal’s main improvement is a generic way to serialize messages. This can be used for transactions, blocks and accounts.
I’m looking forward to your feedback.
Here is a complete LIP draft:
LIP: <LIP number>
Title: A generic serialization method
Author: Maxime Gagnebin <maxime.gagnebin@lightcurve.io>
Andrea Kendziorra <andreas.kendziorra@lightcurve.io>
Type: Informational
Created: <YYYY-MM-DD>
Updated: <YYYY-MM-DD>
Abstract
This LIP proposes a serialization method that is generic, deterministic, size efficient and deserializable.
This method could be used to serialize arbitrary data for hashing and signing but also for storing and transmitting.
This could be applied to (custom) transactions, blocks or account states.
Concrete use cases will be defined in separate LIPs.
The encoding is based on protocol buffers proto2, also referred to as protobuf, with a few additional requirements.
Instead of providing a .proto file, users will specify the serialization schema as a JSON schema.
The encoding is kept compatible with protobuf in the sense that protobuf implementations with the adequate .proto file deserialize binary messages correctly.
Copyright
This LIP is licensed under the Creative Commons Zero 1.0 Universal.
Technical Glossary
- Message: A data structure, such as a JavaScript object.
- Binary message: A sequence of bytes. Our serialization method outputs a binary message.
- Encoding, serializing: Converting a message into a binary message.
- Decoding, deserializing: Converting a binary message into a message.
- Lisk JSON Schema: A JSON schema fulfilling certain restrictions, defined in section Lisk JSON Schemas.
Lisk JSON schemas are used in the Lisk protocol for serialization, deserialization and validation of data.
Motivation
The following points motivate a serialization method that is generic, deterministic, size efficient and allows deserialization:
- When a custom transaction is created, it should be unnecessary to implement a specific serialization function for the transaction.
Instead, it should be sufficient to provide a Lisk JSON schema specifying the template of the transaction. - Parts of the blockchain, like accounts, are not serialized yet.
Having a generic serialization method makes it easy to serialize them. - Storing serialized transactions, blocks or accounts reduces the storage size of the blockchain.
- Sending the serialized transaction or block (instead of the JSON encoding) reduces the size of the messages for peer-to-peer communications.
In particular, this allows new nodes to synchronize faster. - Updating the serialization only requires changing the provided schema.
This implies less development work and reduces the risk of errors.
Rationale
Schemas will be written in the form of a JSON schema. JSON schemas allow to include restrictions and conditions on the data, and are already widely used in the Lisk codebase.
Those restrictions are not used for serializing, but are used with validation tools to make sure that the data follows a strict template.
Using two different schemas for validation and serialization would be possible, but would introduce risks of incompatibilities between the two schemas.
We therefore recommend using the same schema for both validation and serialization.
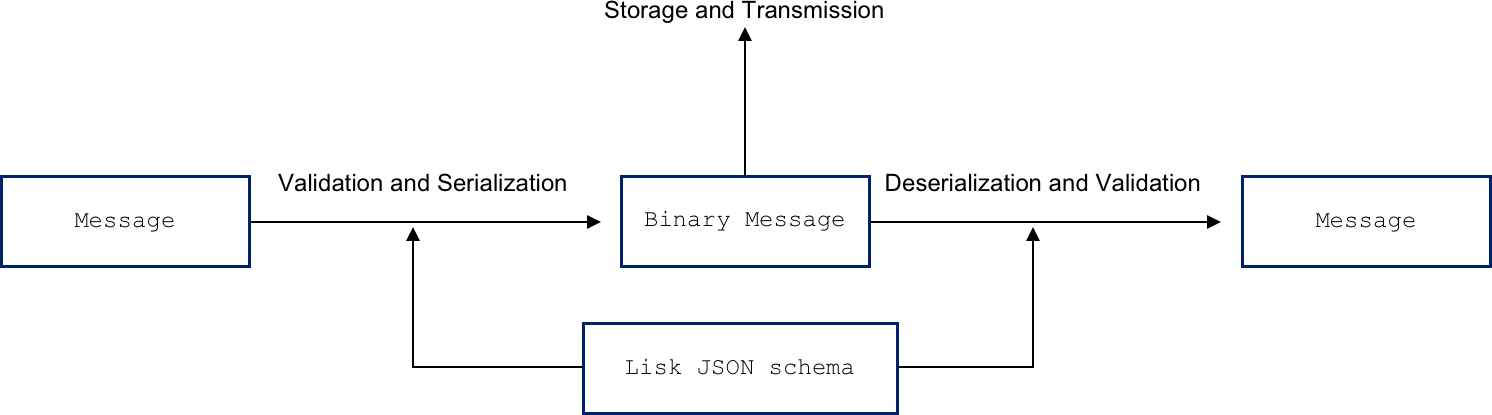
In the Lisk protocol, messages are validated and serialized using the same Lisk JSON Schema. The resulting binary message can be stored and transmitted efficiently. Finally, using the same schema, the binary message can be deserialized, and eventually validated, to recover the original data structure.
Data Types
The Lisk protocol uses the following data types:
- Bytes (or byte array) is widely used, for example to represent key pairs (private and public keys) or signatures. In general, any input or output of a hash function will be of type bytes.
- String is used to represent text, for example usernames of delegates.
-
Integer is used to represent an amount of tokens or other integers, like the height of a block or the transaction type.
- In Lisk, amounts can be larger than 2^53 (90 million LSK).
Therefore, they are not suited to be stored in a JavaScript number and are stored as bigints.
- In Lisk, amounts can be larger than 2^53 (90 million LSK).
- Boolean is used in LIP-0023 to indicate if a delegate is banned or not.
Floating point number is not used in the Lisk protocol and should be avoided in blockchain applications. If the need to represent fractional parts of an object arises, it is best to define a new fractional object (like Beddows in Lisk) and then consider integer amounts of this fractional object.
JSON Types
The JSON schema specifications describe the “type” keyword. This keyword should usually be used to define the data type of a property. However, this keyword has two drawbacks for our use case:
- There is no value for “type” specifying a byte array.
We could use string or object to represent bytes.
This is however confusing and could lead to errors.
Validation is also a concern here, the only type validating a byte array in JavaScript is object.
But object also validates other values, like dictionaries. - “Integer” can be specified as a JSON type.
The JSON specifications do not limit the range of integers.
However, in JavaScript, large numbers (greater than 2^53) have to be represented by bigints, whereas smaller integers can be represented by numbers.
This implies that the schema would need an additional keyword to specify the range of the variable and its potential sign (signed or unsigned).
As per validation, the validation library currently used in Lisk (ajv) does not validate a bigint value as an integer.
Validating bigints as integers would require modifying the validation libraries, or writing our own.
Several other standards exists to try to solve this problem, see for example: Google API Discovery Service or OpenAPI Specification version 3.
Those two solutions rely on the format keyword to relay additional information about the type.
As the format keyword already exists in the JSON specifications, this might seem a good solution, but brings additional drawbacks:
format is intented to be used for strings.
Extending format to integers or objects will not be supported by most JSON validators.
Those specifications are therefore neither totally satisfactory, nor do they solve the issue of JSON validation.
To solve the above shortcomings of JSON schema validation, we propose to introduce a new keyword in Lisk JSON Schemas: “dataType”.
Using a new keyword avoids any risks of unwanted behavior due to reuse of an existing keyword.
We use this new keyword to specify any “scalar” type:
“bytes”, “uint32”, “sint32”, “uint64”, "sint64, “string” or “bool”.
The “type” keyword is kept for “structural” type: “object” or “array”.
In particular, the “type” keyword cannot have the values: “integer”, “number”, “boolean”, “string” or “null” in our schemas.
Protobuf Encoding
The encoding specification of this proposal is based on Protocol Buffers, a widely used language-neutral serialization method.
The encoding and decoding rules were chosen in such a way that any decoder following the protobuf specification with the correct .proto file decodes binary messages correctly.
Hence, third party implementations could use other protobuf implementations to decode binary messages derived from this protocol.
Appendix B describes how to create a .proto file corresponding to a Lisk JSON Schema.
The same cannot be achieved for serializing data: protobuf’s specification does not specify a deterministic encoding order.
Hence, it cannot be guaranteed that an arbitrary protobuf implementation will serialize data as specified in this protocol.
Other serialization protocols used in the industry have been considered.
For example, Ethereum uses a custom serialization method called RLP (Recursive Length Prefix), and it is planning to move to SSZ (Simple Serialize).
These protocols are deterministic, and as such would be viable candidates for these specifications.
However, we think that protobuf is better suited to encode generic data structures.
Further, it has a much larger userbase reaching outside the blockchain ecosystem.
This makes it the prefered choice to allow an easy integration of Lisk with third-party libraries.
Encoding Default Values
The encoding procedure should encode messages as faithfully as possible. In this regard, our encoding follows the proto2 specifications: properties set to a default value are encoded. Furthermore, our encoding does not include missing properties in the binary message.
For example, a block header with empty bytes (the default value for bytes) in the signature property is not encoded to the same binary message as a block header with a missing signature property.
Uniqueness of Encoding
Special care should be taken when creating binary messages.
If the binary message, binaryMsg, is not valid, it could be that encode(decode( binaryMsg )) != binaryMsg.
This could cause a signature validation to fail or could generate a distinct ID for seemingly the same transaction.
This happens because the decoder populates missing fields with their default values and the encoder will reorder the fields.
This is not the case for valid binary messages properly generated by the Lisk protocol, and will not be the case if all fields are set to their default value before encoding.
To ensure that this does not create future issues, we suggest to specify every property of custom assets as required.
In Lisk JSON Schemas, this is done by including the name of the property in the array value of the required keyword of the object.
This guarantees that unset fields are detected on the validation layer and that invalid binaries are not generated.
A possible way to assess the validity of a binary message is to check that encode(decode( binaryMsg )) == binaryMsg.
If this is not the case, the original binary message was not properly generated and should be rejected.
Arrays of Arrays
The specifications below state that the data type of elements of an array should be specified in the value of items.
It is also specified that the value of items cannot be of type array.
This may suggest that nested arrays are not supported at all.
However, one can easily circumvent this limitation by wrapping the inner array of a nested array into an object.
The example below shows a property of type array where each element is an array of strings (wrapped into an object).
This will be encoded in the same way as nested repeated objects in protobuf.
| Lisk JSON Schema | Corresponding Protobuf Message |
|
|
Specification
Overview
A Lisk JSON Schema has to be provided for each data structure for which instances (also referred to as messages) will be serialized.
The same schema is used whenever a binary message is deserialized into an instance of this data structure.
The next subsections are structured as follows:
- In Lisk JSON Schemas, we define the requirements that a JSON schema needs to fulfill in order to be a Lisk JSON Schema.
- In Encoding, we give the encoding rules to be used. Those are obtained by making the protobuf encoding rules more strict.
- In Uniqueness of Binary Messages, we give the rules that the binary message has to respect to be considered valid by the Lisk protocol.
- In Decoding, the conversion of binary messages to JavaScript objects is defined.
Lisk JSON Schemas
A Lisk JSON Schema is a JSON schema according to draft 7 of “JSON Schema: A media Type for Describing JSON Documents” (see the core specification and the validation specification) with the following additional rules:
- The root schema must be of type object.
- Every schema of type object must have the
propertieskeyword. - Every property of a schema of type object must follow:
- Exactly one of the keywords
dataTypeortypemust be included. It must have a value from the encoding table. As a consequence, the value oftypecannot be “null”, “number”, “integer”, “string”, “boolean” or an array of values. - The keyword
fieldNumbermust be included. All values used forfieldNumberin a given object have to be different; nested objects can reuse the same values forfieldNumber.
This value is used to generate the key in the binary message.
Values forfieldNumberhave to be integers greater or equal than 1 and strictly smaller than 19000.
As a consequence, every object must have less than 19000 properties.
- Exactly one of the keywords
- We restrict properties of type array to list validation where each item matches the same schema.
A property of type array must have theitemskeyword and its value is a schema specifying the repeated schema.
The value of items must include exactly one of the keywordsdataTypeortype.
This keyword must have a value from the encoding table, but it is not allowed to be “array”. - Keywords other than
type,dataType,properties,itemsandfieldNumberwill be ignored by the serialization process.
DataType Keyword
We introduce the dataType keyword. The possible values for this keyword are: “uint32”, “sint32”, “uint64”, “sint64”, “bytes”, “string” and “boolean”. The values associated with properties with those keywords have to validate as follows.
| If data is of "dataType" | JavaScript Validation |
| bytes |
|
| uint32 |
|
| sint32 |
|
| uint64 |
|
| sint64 |
|
| string |
|
| boolean |
|
Encoding
The encoding specified in this document follows the protobuf specification proto2 with some additional restrictions.
For the sake of completeness, we recall some of the protobuf features.
Base 128 Varints
In binary messages, integer values are encoded using varints.
Varints are an efficient way to encode numbers without needing to explicitly specify the length of the byte sequence.
In general, smaller numbers take a smaller number of bytes.
Encoding Objects
All instances to be encoded by the Lisk protocol are object instances.
All properties of the object are encoded as key-value pairs. Keys and values are generated according to the sections below.
The key-value pairs are then concatenated into a byte string in increasing fieldNumber order.
Keys
The key can be of two different wire types, either type 0 or type 2.
The wire type is dependent on the data type of the property and is specified in the encoding table below.
- Keys of wire type 0 are constituted of 1 varint: They are the varint encoding of 8*
fieldNumber.
This is equal to the varint encoding of (fieldNumber<< 3) | 000 . - Keys of wire type 2 are constituted of 2 varints. The first is the varint encoding of 8*
fieldNumber+2.
This is equal to the varint encoding of (fieldNumber<< 3) |010.
The second is the varint encoding of the length of the byte sequence to follow.
Encoding Summary Table
Starting from a Lisk JSON Schema, the properties are encoded as in the following table. Each data type encoding is described in detail in the next sections, accompanied with a few examples.
| Data Type in Lisk JSON Schema | Value encoded as | Wire type of Key |
|---|---|---|
| "dataType": "uint32", "uint64" | varint | 0 |
| "dataType": "sint32", "sint64" | varint, according to signed integer | 0 |
| "dataType": "boolean" | 0x00 = false
0x01 = true |
0 |
| "dataType": "string" | byte sequence with utf8 encoding. | 2 |
| "dataType": "bytes" | byte sequence (itself) | 2 |
| "type": "object" | series of key-value pairs as described above | 2 |
| "type": "array"
"items":someSchema |
If someSchema is of numeric or boolean type:
If someSchema is not of numeric or boolean type:
SomeSchema cannot be of type array. |
2 |
Encoding Booleans
Boolean values are encoded as per the following table. Their key is of wire type 0.
| Boolean | In hexadecimal |
|---|---|
| true | 01 |
| false | 00 |
Encoding Integers
Integers are encoded as varints. Signed integer (sint32 and sint64) follow the protobuf specifications for signed integers. Notice that they are different than int32 and int64. Their key is of wire type 0.
| uint32 or uint64 | Binary | Varint | Varint in hexadecimal |
|---|---|---|---|
| 0 | 0b0 | 00000000 | 00 |
| 1 | 0b1 | 00000001 | 01 |
| 45 | 0b101101 | 00101101 | 2d |
| 678 | 0b1010100110 | 10100110 00000101 | a6 05 |
| sint32 or sint64 | Binary | Varint | Varint in hexadecimal |
|---|---|---|---|
| 0 | 0b0 | 00000000 | 00 |
| -1 | 0b1 | 00000001 | 01 |
| 1 | 0b10 | 00000010 | 02 |
| -2 | 0b11 | 00000011 | 03 |
| 45 (encoded the same as uint 90) | 0b1011010 | 01011010 | 5a |
| -678 (encoded the same as uint 1355) | 0b10101001011 | 11001011 00001010 | cb 0a |
Encoding Strings and Bytes
Bytes are encoded as themselves and strings are encoded as their UTF-8 encoding. Their key is of wire type 2, generated with the fieldNumber and the length of the bytes, or the length of the UTF-8 encoding of the string.
| string or byte array | encoded as |
|---|---|
| “” | (empty bytes) |
| “lisk” | 6c 69 73 6b |
| ef6245a4aa | ef6245a4aa |
Encoding Arrays
Arrays of numeric types and boolean are always encoded packed.
As such, arrays of string, bytes or object are encoded differently from arrays of uint32, sint32, uint64, sint64 or boolean.
Arrays of arrays are not directly supported.
Arrays of Varints or Booleans
Arrays of uint32, sint32, uint64, sint64 and boolean are encoded packed. The encoding is obtained by the following procedure:
- Encode each element of the array as a varint.
- Concatenate the outputs of step 1, respecting the order of the original array.
- If the length of the array is non-zero, the output of step 2 is then encoded as data type bytes.
If the array is of length zero, it is not encoded in the binary message.
| Object Schema | Object instance | Encoded as |
|---|---|---|
|
|
1a 03 2d a605 |
Array of String, Object and Bytes
Arrays of those types are encoded differently than numeric types or booleans. The encoding is obtained by the following procedure:
- Encode each element of the array with a key generated with the same number obtained from the
property.fieldNumber. - Concatenate the outputs of step 1, respecting the order of the original array.
| Object Schema | Object instance | Encoded as |
|---|---|---|
|
|
1a 04 6c69736b 1a 00 1a 03 4c534b |
Uniqueness of Binary Messages
The protobuf proto2 specifications are flexible with the order in which different fields are encoded and the presence of additional fields in a binary message.
We do not allow such flexibility.
A binary message is valid, with respect to the corresponding data and schema, if the following rules are respected:
- All properties are encoded according to the rules explained in Encoding.
- All properties of objects are ordered in the binary message with respect to their
fieldNumber.
In particular, when an object is serialized, its properties are added to the binary message by increasingfieldNumber.
As a consequence, all elements of an array must be added consecutively to the binary message. - The binary message contains exactly one value for each property specified in the schema.
There are three exceptions to this rule:- Empty Arrays do not appear in the binary message.
- Non-packed arrays may contain multiple values.
- Non-required properties for which no value was provided do not appear in the binary message.
- The binary message does not contain properties not present in the schema.
A few examples are available in the Testing and Examples section, and more can be found in the protobuf documentation.
Decoding
When a binary message is parsed, the binary message is decoded according to the proto2 specifications.
In particular, the following rules will be applied:
- Missing values: Whenever a binary message does not contain a specific field, the corresponding field in the parsed object is set to its default value. The default value is type-specific:
- For strings, the default value is the empty string.
- For bytes, the default value is the empty bytes.
- For booleans, the default value is false.
- For numeric types, the default value is zero.
- For arrays, the default value is the empty array.
- For objects, the default value is an object in which each of the properties is set to its default value.
- Unknown fields: When a binary message contains an unknown field, i.e., an unknown field number, then this field is not parsed and simply discarded. It is important to note that this is a divergence with most protobuf implementations where unknown fields are stored.
The entries are then stored as follows in the JavaScript object:
| Data Type in Lisk JSON Schema | Decoded as |
|---|---|
| “dataType”: “uint32” or “sint32” | number |
| “dataType”: “uint64” or “sint64” | bigint |
| “dataType”: “boolean” | boolean |
| “dataType”: “string” | string |
| “dataType”: “bytes” | Buffer |
| “type”: “array” | array |
| “type”: “object” | object |
Testing and Examples
This section is meant to help understand the above specification as well as to test future implementations.
It does not show a schema example used in the Lisk protocol.
The Lisk JSON Schemas used by the Lisk protocol are specified in separate documents.
Simple Examples
| Lisk JSON Schema | Object instance | Encoded in hexadecimal as |
|---|---|---|
|
|
18 2d 38 cb0a |
|
|
38 cb0a b02a 2d |
|
|
18 2d 38 cb0a 8a02 04 6c69736b |
More involved example
| A Lisk JSON Schema | The corresonding proto message |
|---|---|
|
|
Data Example 1:
example1 = {
amount: 3n,
name: "me",
myObject : {
myAge: 543,
data : empty bytes,
},
myArray:[], //NB: this does not appear in the binary
}
Will be encoded as 14 bytes: 08 03 12 02 6d 65 2a 06 1a 00 88 01 9f 04
Data Example 2:
example2 = {
amount: 3n,
name: "me",
myObject : {
myAge: 543,
data: bytes from 0xab 0xcd 0xef,
},
myArray : [
{
newName: "you",
aBoolean: false,
numbers: [1,-2,678]
}]
},
}
Will be encoded as 32 bytes: 08 03 12 02 6d 65 1a 0d 0a 03 79 6f 75 10 00 1a 04 02 03 cc 0a 2a 09 1a 03 ab cd ef 88 01 9f 04
Data Example 3
example3 = {
amount: 3n,
name: "me",
myObject : {
myAge: 543,
data: bytes from 0xab 0xcd 0xef,
},
myArray : [
{
newName: "you",
aBoolean: false,
numbers: [1,-2,678]
},
{
newName: "they",
aBoolean: true,
numbers: [] //NB: this will not appear in the binary
},
]
}
Will be encoded as 44 bytes: 08 03 12 02 6d 65 1a 0d 0a 03 79 6f 75 10 00 1a 04 02 03 cc 0a 1a 08 0a 04 74 68 65 79 10 01 2a 09 1a 03 ab cd ef 88 01 9f 04
Backwards Compatibility
There are no incompatibilities since the protocol is not changed.
Applications of the proposed serialization method will be proposed in separate LIPs.
Appendix A: Examples
Invalid JSON schemas
-
Root schema does not specify an object:
{ "dataType": "string" } -
Root schema does not have the
propertieskeyword:{ "type": "object" } -
dataTypeortypeis not specified for the propertya:{ "type": "object", "properties": { "a": { "maxLength": 5 } }, "required": ["a"], } -
dataTypeandtypeare both specified for the propertya:{ "type": "object", "properties": { "a": { "dataType": "uint32", "dataType" : "string", } }, "required": ["a"], } -
The keyword
fieldNumberis missing for the propertya:{ "type": "object", "properties": { "a": { "dataType": "uint32" } }, "required": ["a"] } -
The keyword
propertiesis missing for the propertya:{ "type": "object", "properties": { "a": { "type": "object", "fieldNumber": 1 } }, "required": ["a"] } -
The property
ais of type array, but theitemskeyword is missing:{ "type": "object", "properties": { "a": { "type": "array", "fieldNumber": 1 } }, "required": ["a"], } -
The items of the array
ahave several types:{ "type": "object", "properties": { "a": { "type": "array", "fieldNumber": 1, "items": ["string", "integer"] } }, "required": ["a"], }
Appendix B: JSON Schema to Protobuf
Protobuf is a very popular mechanism for serializing structured data.
Therefore we aim to be compatible with third party libraries wanting to read the Lisk encoded data with their protobuf implementation.
This section describes how to derive a .proto file from a Lisk JSON Schema.
The Testing and Examples section contains examples of JSON schemas and corresponding .proto files.
Field Name and Field Number
All properties in Lisk JSON Schemas have a name and a fieldNumber.
This value is used when creating the keys in the binary messages and should be used as the field name and field number when creating the .proto file.
To make sure that the fieldNumber specified in the Lisk JSON Schema is compatible with protobuf, we restrict the value of fieldNumber to the range 1 to 18’999.
Type Conversion
The following table specifies how the type for the field in the protobuf message should be chosen with respect to a given property in the Lisk JSON Schema.
| Data Type in Lisk JSON Schema | Field type in proto message |
|---|---|
| Not used | double, float, fixed32, fixed64, sfixed32, sfixed64, int32 and int64 |
"dataType": "uint32", "sint32", "uint64" or "sint64"
|
uint32, sint32, uint64, sint64 (respectively) |
"dataType": "boolean" |
bool |
"dataType": "string" |
string |
"dataType": "bytes" |
bytes |
"type":"array" with items: {dataType or type : someType}
|
repeated field with type given by someType |
"type": "object" |
a nested message type representing the object in question |
Pseudo Code
Let schema be a fixed JSON schema. Then the corresponding .proto file can be obtained by taking the output of create_proto_message_type_for_object("rootMessage", schema) from the pseudo code below.
NESTED_MESSAGE_PREFIX = "NM_"
get_type(schema):
if schema.type:
return schema.type
return schema.dataType
is_scalar_type(dataType):
if dataType in {"uint32", "uint64", "sint32", "sint64", "boolean", "string", "bytes"}:
return True
return False
get_proto_type_for_scalar_json_type(dataType):
if dataType == "boolean":
return "bool"
return type
create_proto_message_type_for_object(messageName, jsonSchema):
create a proto message type, MSG, with the name messageName
for each key in jsonSchema.properties
propSchema = jsonSchema.properties[key]
type = get_type(propSchema)
fieldNumber = propSchema.fieldNumber
if is_scalar_type(type):
fieldString = "optional " + get_proto_type_for_scalar_json_type(type)
else if type == "object":
nestedMessageName = NESTED_MESSAGE_PREFIX + key
nestedMessage = create_proto_message_type_for_object(nestedMessageName, propSchema)
fieldString = "optional " + nestedMessageName
else if type == "array":
fieldString = "repeated "
itemsType = get_type(propSchema.items)
if is_scalar_type(itemsType):
fieldString += get_proto_type_for_scalar_json_type(itemsType)
else:
# itemsType must be "object"
nestedMessageName = NESTED_MESSAGE_PREFIX + key
fieldString += nestedMessageName
nestedMessage = create_proto_message_type_for_object(nestedMessageName, propSchema)
fieldString += " " + key + " = " + fieldNumber + ";"
add the field specified by fieldString to MSG
if nestedMessage:
add the message nestedMessage as a nested message to MSG
return MSG